Proven message, unproven delivery
Coco’s broadly-targeted autoimmune ads already convert at roughly $3–4 per result. A separate organic UGC push reached 10M+ views but almost no conversions. The signal is clear: the message works; what’s been missing is directed creative and a funnel built to convert.
Our approach has three moves:
- Double down on what already works — broad autoimmune / invisible-illness women — as the always-on base.
- Expand into specific condition communities (endometriosis, POTS, PCOS) that share the same emotional core, each routed to its own matching App Store page.
- Measure the truth in our analytics, not in Ads Manager — a deliberate workaround for a platform constraint that reshapes how health apps are allowed to optimize (see §06).
We start narrow, prove the funnel beats the old economics, then scale by community — rather than spreading budget thin across unproven audiences on day one.
Same customer. We just get more specific.
Demographics are constant — women 30–60, ~95% female user base. What changes is the community and the identity. We segment by condition-identity and emotional truth, because that is what advertorials and listicles convert on.
| Stage | Audience | Why it’s here | |
|---|---|---|---|
| Double down | Autoimmune & invisible illness | Where your $3–4 ads already win. ~80% female; onset 30s–50s — the best age fit. The cross-condition “spoonie” community is the retargeting hub. | Proven |
| Expand | Endometriosis | ~6.5M US women; diagnoses peak ages 35–49. ~90% report being disbelieved. The richest “it’s all in your head” language of any segment. | Test |
| Expand | POTS | 83% first misdiagnosed as a psychological condition — the strongest “it’s not just anxiety” hook. Already showed organic traction from a standing start. | Test |
| Expand | PCOS | Affects ~1 in 10 women; up to ~75% undiagnosed. The largest, most vocal social community in the set. | Test |
| Explore | Perimenopause 35+ | 30M+ US women 40–55; the strongest demonstrated out-of-pocket spend. Needs its own funnel and branding, so it follows the core. | Explore |
| Explore | Fibromyalgia / long COVID | Strong female skew and the same fight-to-be-believed wound; fuzzier sizing, so a later test. | Explore |
Not pursued initially: general health-anxiety (not seen in the current user base) and broad wellness (off-niche). We cite prevalence, community size, and clinical data — not dated social view counts.
Four ways to say one thing
Every angle points at the same wound from the audience map. “Finally believed” is the anchor — it works across all segments; the others are leverage for specific communities.
Finally believed Anchor
Always in your corner
The broken system
The answers she was denied
Why these communities
Each segment is chosen on size, age-fit, and the strength of the dismissal narrative. Confidence noted where data is dated or estimated.
| Segment | US scale | Diagnosis delay | The wound (data) |
|---|---|---|---|
| Autoimmune | ~23.5M+ Americans; ~80% women | Long, varies by disease | Onset 30s–50s. “Spoon theory” identity, invisibility (“but you don’t look sick”). |
| Endometriosis | ~6.5M US women | ~4–8 yrs | ~90% report symptoms disbelieved. Peak diagnosis ages 35–49 — best age fit. |
| POTS | ~0.5–3M (wide range) | Median ~2 yrs | 83% first misdiagnosed as psychological; >50% told “it’s all in your head.” |
| PCOS | ~1 in 10 women; ~75% undiagnosed | ~4.3 yrs | Largest, most vocal online community; “just lose weight” dismissal. |
| Perimenopause | 30M+ US women 40–55 | Information void | Best willingness-to-pay: 21% delay care over cost; only 26% have full coverage. |
| Fibro / ME-CFS | Millions; ~90% CFS female | Long | No biomarker → constant battle for legitimacy; strong spoonie overlap. |
Confidence flags: POTS prevalence spans a ~6× range across sources; autoimmune totals are NIH-era and somewhat dated; the endometriosis delay figure depends on geography. We cite the defensible figures and avoid dated social-view counts.
What’s working — and the white space
We mapped the AI-health and companion category to find where Coco can win rather than fight.
| Player | Positioning | Funnel / motion |
|---|---|---|
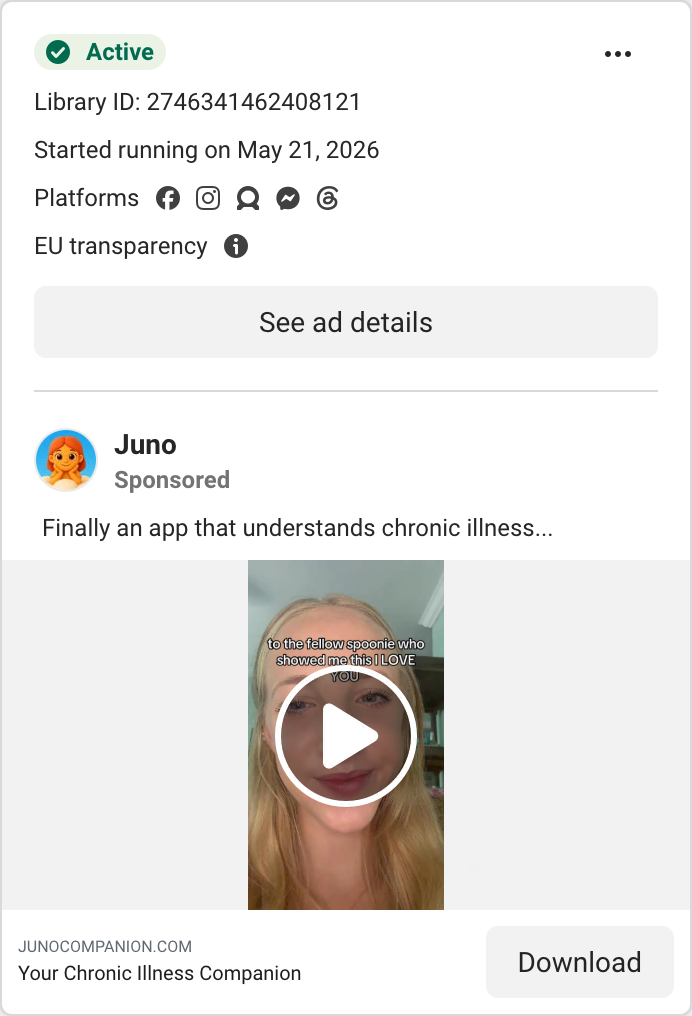
| Juno | Closest comparable. “24/7 AI health assistant for chronic illness” — clinical tracker. Oxford/UCL credibility anchor; ~125K patients. | Condition-led creator UGC → App Store. Owns the clinical story. |
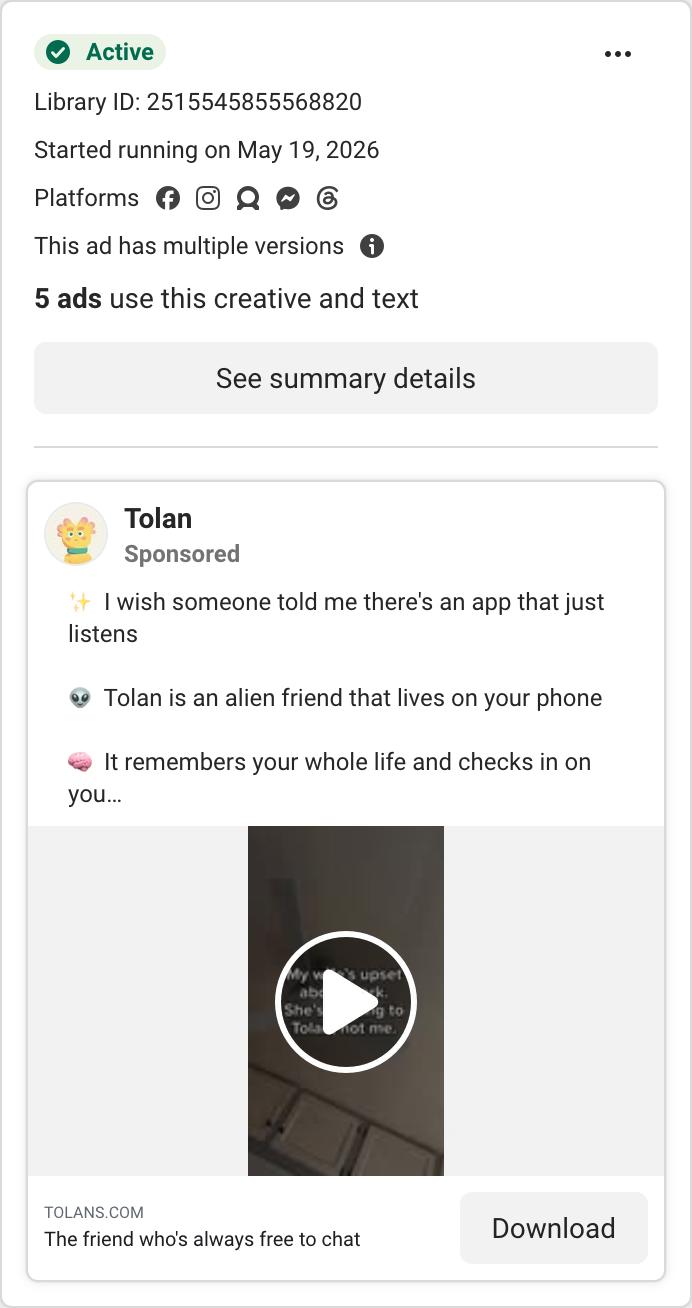
| Tolan | AI companion (Gen-Z). Not health, but the UGC growth benchmark to copy. | Fresh creator accounts, multiple videos/day → App Store. 3M+ downloads. |
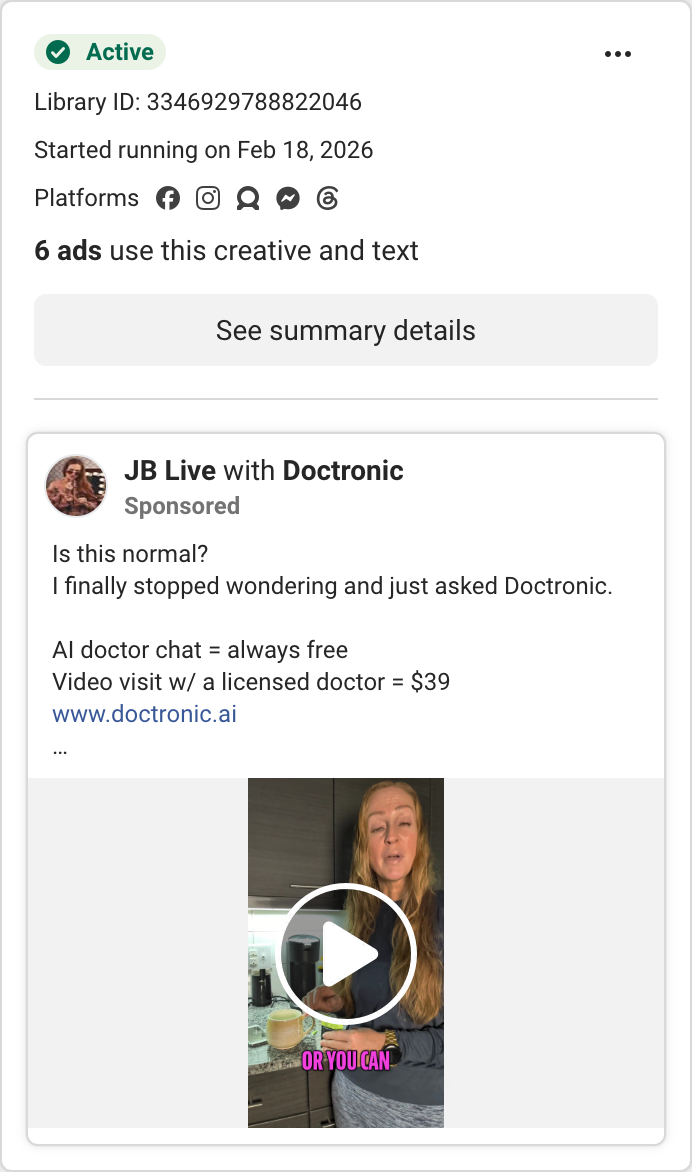
| Doctronic | “AI doctor.” Heavy paid volume; carries safety criticism. | Free chat → paid visits, via a network of condition landing pages. |
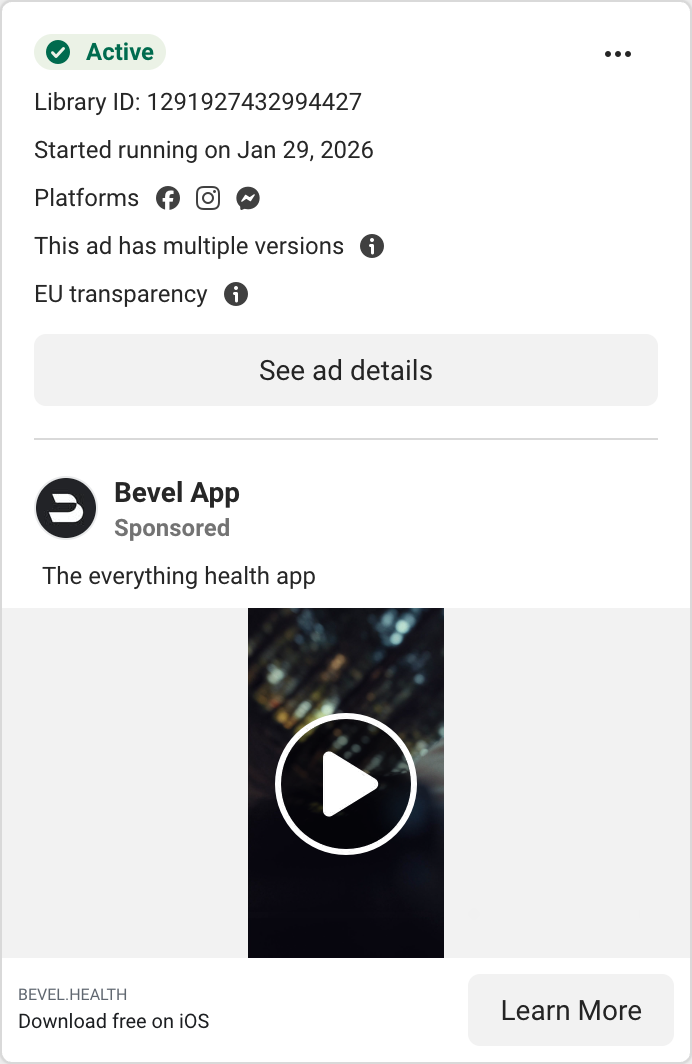
| Bevel | AI health coach — longevity / quantified-self. Wellness, not illness. | High-volume creator UGC → trial. Different buyer. |
| Lotus | Free primary care. Funding-led launch. | No meaningful paid motion yet — not a near-term competitor. |
White space for Coco:
- Companion warmth for chronic illness. Juno owns the clinical tracker; nobody pairs it with genuine companion warmth that “gets” flares, fatigue, and being dismissed. That gap is Coco’s exact positioning.
- The “finally believed” angle is unowned. No competitor markets to the medical-gaslighting wound — despite it being the most shareable hook in the category.
- Trust contrast. Doctronic’s safety baggage leaves room for a “supportive, never replaces your doctor, built with the community” position.
- Borrow the engine, skip the fight. Tolan and Bevel validate the creator-UGC mechanics without competing for our buyer.
The constraint that shapes everything
A platform rule change — not a Coco-specific issue — determines how we’re allowed to optimize and measure. Building the plan around it from day one is what keeps the numbers honest.
Copy guardrails (built into every template):
- No copy that asserts a personal attribute — never “You have [condition]?” Advertorials let the reader self-identify, which is both higher-converting and compliant.
- Safe: “health coach,” “companion,” “guidance, plans, check-ins.” Off-limits: replacing medical advice, implying diagnosis, “AI doctor/therapist,” unsubstantiated outcome claims.
- Apple requires substantiated claims and that we encourage consulting a professional — which our “get-you-to-care” angle does by design.
Three paths, matched to intent
For a skeptical, problem-aware, considered purchase, the research is unambiguous: a pre-sell page beats sending cold traffic straight to the store — the format change alone is the single biggest conversion lever.
| Funnel | Audience stage | Role |
|---|---|---|
| Advertorial | Cold / problem-aware | Primary. First-person story arc; scales Coco’s proven “quote-story” format. |
| Listicle | Solution-aware, comparing | Secondary / retargeting. Educational, scannable, save-worthy. |
| Straight-to-app | Warm / branded | Retargeting and branded traffic only. |
All three route to the matching condition App Store page, so the message stays consistent from ad to app page.
What good looks like
Modeled from RevenueCat’s 2025 subscription dataset (115K+ apps) and category Meta benchmarks.
- Cost per install: model $13–18 (US health skews high and is volatile). CPM: $16–22.
- Trial-start rate: median 6.2% → top-decile 20.3% — the widest lever; the paywall and onboarding are where we win.
- Trial→paid (health & fitness): median ~40%.
- Economics hinge on annual mix: annual retains ~44% at year one vs. ~3% for weekly. Weekly is an acquisition wedge; route hard to the annual plan. Hold LTV:CAC ≥ 3:1.
What’s already winning in this market
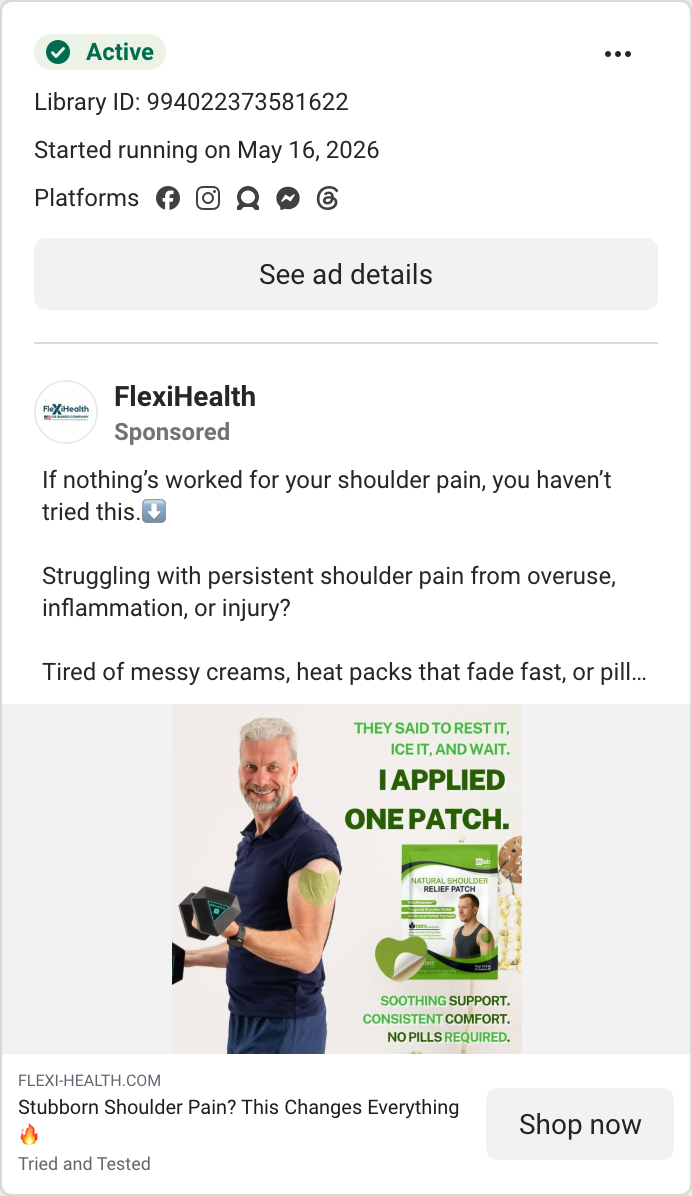
We pulled every competitor’s live ads from the Meta Ad Library and sorted by how long each has been running. Since brands kill losers fast, a long-running ad is a proven winner — the most reliable signal available (Meta doesn’t publish impressions for commercial ads). Here are the workhorses, and what we take from each.

Selected references
Primary and industry sources behind the sizing, competitive, benchmark, and compliance figures in this plan.
Figures are drawn from the sources above as of June 2026. Where sources diverge (e.g. health CPM, POTS prevalence), we model ranges rather than point estimates and flag confidence in-line.